
Customized image generation, which seeks to synthesize images with consistent characters, holds significant relevance for applications such as storytelling, portrait generation, and character design. However, previous approaches have encountered challenges in preserving characters with high-fidelity consistency due to inadequate feature extraction and concept confusion of reference characters. Therefore, we propose Character-Adapter, a plug-and-play framework designed to generate images that preserve the details of reference characters, ensuring high-fidelity consistency. Character-Adapter employs prompt-guided segmentation to ensure fine-grained regional features of reference characters and dynamic region-level adapters to mitigate concept confusion. Extensive experiments are conducted to validate the effectiveness of Character-Adapter. Both quantitative and qualitative results demonstrate that Character-Adapter achieves the state-of-the-art performance of consistent character generation, with an improvement of 24.8% compared with other methods.
We present Character-Adapter, a novel framework designed to facilitate consistent character generation. Specifically, it incorporates a prompt-guided segmentation module that localizes image regions based on text prompts, thereby facilitating adequate image feature extraction. Subsequently, we introduce a dynamic region-level adapters module, comprising region-level adapters and attention dynamic fusion. The region-level adapters allow each adapter to concentrate on the corresponding region (e.g., attire, decorations) of the generated image, thereby mitigating concept fusion and promoting disentangled representations facilitating adequate image feature extraction. Additionally, the attention dynamic fusion is introduced to enable more accurate conditional image feature preservation while facilitating coherent generation between the character and the background regions. As illustrated in the figure, we first segment a reference character into several parts using prompt-guided segmentation. Subsequently, We obtain the attention maps of the target image layout using the same approach. Finally, we utilize dynamic region-level adapters to achieve detailed and consistent character generation.
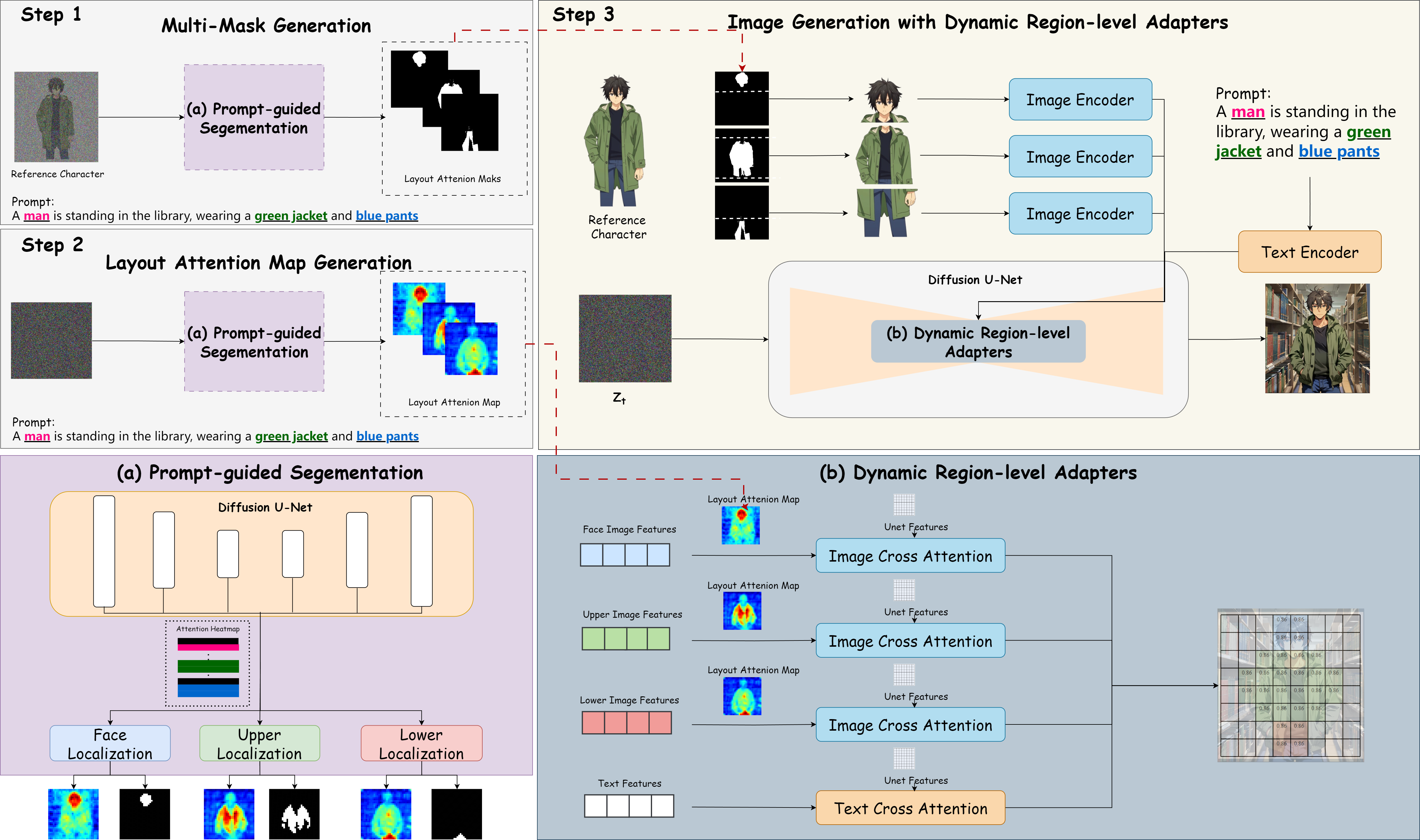
Adavantages: (1) We do not need extra training. Character-Adapter can be applied to any model you want. (2) We maintain high fidelity of the given characters as well as text-image alignment. (3) Our method can be applied not only to generate characters but also to create general objects.

Character-Adapter is designed to generate highly consistent characters with intricate details. Its advantage of not necessitating further training allows it to be more versatile and practical in its applications. This can generate not just characters, but also objects in other domains.


Character-Adapter’s versatility and compatibility. (a) Combination with Pose Control. (b) Inpainting with a reference image. (c) Generation with animals (other types).
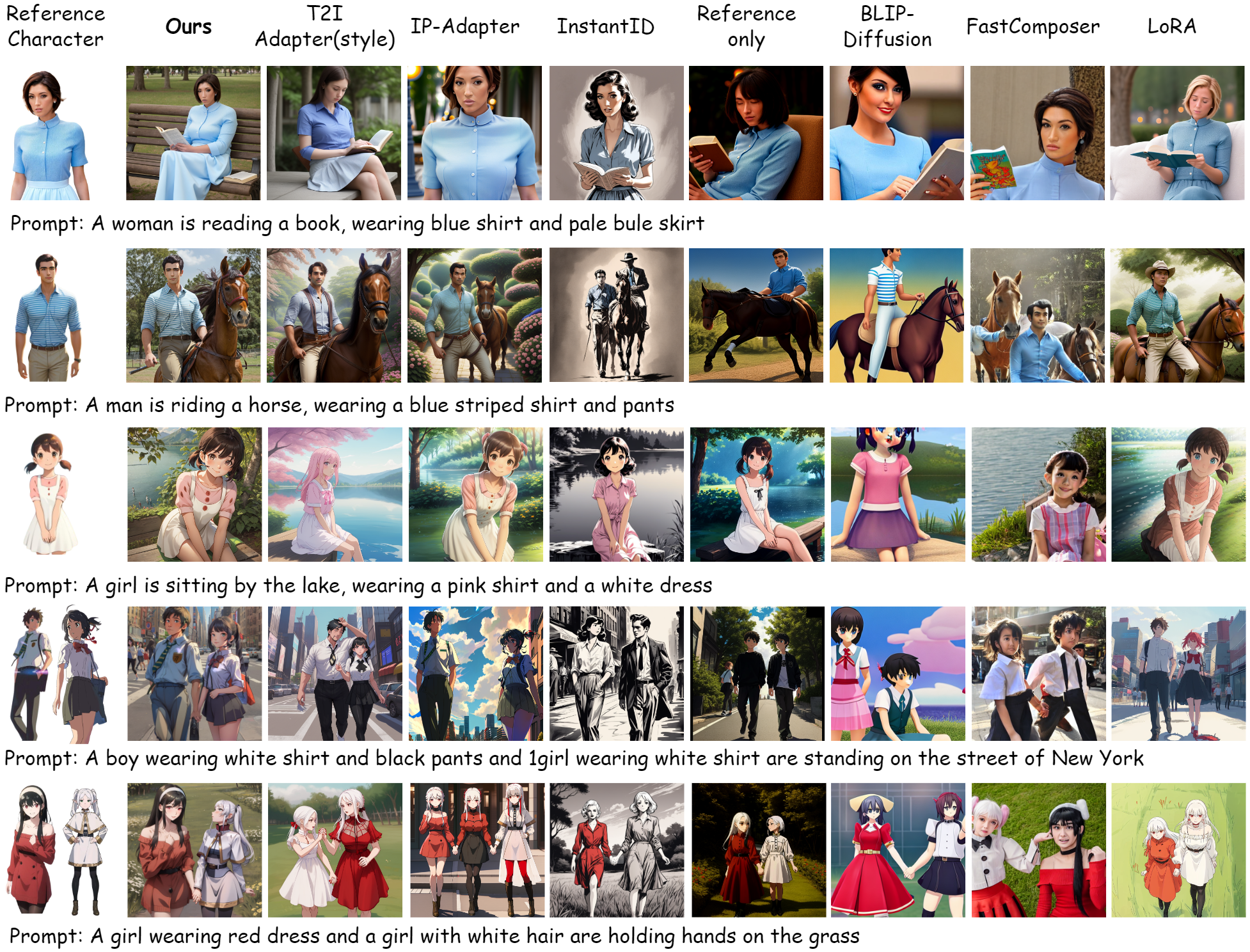
Compared with other methods, including both fine-tuned and training-free methods, Character-Adapter generates high-fidelity multi-character images with intricate details while preserving text-image alignment.
@misc{ma2024characteradapter,
title={Character-Adapter: Prompt-Guided Region Control for High-Fidelity Character Customization},
author={Yuhang Ma and Wenting Xu and Jiji Tang and Qinfeng Jin and Rongsheng Zhang and Zeng Zhao and Changjie Fan and Zhipeng Hu},
year={2024},
eprint={2406.16537},
archivePrefix={arXiv},
primaryClass={id='cs.CV' full_name='Computer Vision and Pattern Recognition' is_active=True alt_name=None in_archive='cs' is_general=False description='Covers image processing, computer vision, pattern recognition, and scene understanding. Roughly includes material in ACM Subject Classes I.2.10, I.4, and I.5.'}
}